
在 .Net 中关于 Dictionary (哈希表) 的一些细节
一、设计细节
1. 数据存储
Dictionary 的底层采用了比较传统的 数组 + 链表 的设计。而在其他语言的标准库实现中,例如 Java ,可能会在此基础上使用 红黑树 来替换 链表 进行进一步的优化。
存入的数据会被封装为类似链表节点的名为 Entry 的结构。
private struct Entry
{
public uint hashCode;
/// <summary>
/// 0-based index of next entry in chain: -1 means end of chain
/// also encodes whether this entry _itself_ is part of the free list by changing sign and subtracting 3,
/// so -2 means end of free list, -3 means index 0 but on free list, -4 means index 1 but on free list, etc.
/// </summary>
public int next;
public TKey key; // Key of entry
public TValue value; // Value of entry
}Entry 的实例本身被保存在 entries 数组中,该数组的长度是 Dictionary 的容量值 Size 。
该结构中可见使用 next 字段保存了指向下一个对象的索引,从而形成一个链表。
存入数据时,先通过 GetHashCode() 方法获取到 Key 的哈希值 ,再使用哈希值对 Size 取余,得出该数据的哈希值被钳制在 [0, Size) 范围内的对应余数,从而可以与数组索引进行对应。
但是由于可能存在哈希冲突,即不同的哈希值取余后得到相同的余数,因此该索引值不会直接与 entries 数组进行对应。而是引入一个桶 buckets 数组,该数组存储一个桶的索引值。
桶相当于链表,发生哈希冲突的数据将会被存储在同一个桶中。 buckets 数组中存储对应桶的第一个元素在 entries 数组的索引值。
参考下图:
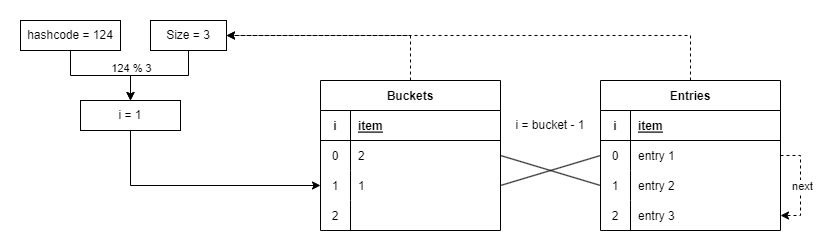
理想情况下,即在 GetHashcode() 方法实现合理时,数据应当能均匀分布在各个桶中。此时Dictionary 的存储和查找方法都可以达到 O(1) 的时间复杂度。
而最坏情况下,即所有 GetHashcode() 返回值都造成哈希冲突时,所有数据映射到同一个桶中,则该数据结构退化为 链表,其时间复杂度也可能退化为 O(n) 。
因此有的实现也会使用 红黑树 来优化 链表,红黑树 在最坏情况下仍能够拥有 O(log n) 的时间复杂度。
2. 扩容操作
由于 Dictionary 使用数组来存储数据,因此其会拥有与数组列表 ArrayList 类似的性质,即当元素数量接近容量 Size 时,需要进行扩容操作。
在上文中我们知道了 Dictionary 中的元素索引与容量 Size 存在密切的关系,因此 Dictionary 的扩容不仅仅需要复制数据,还需要重新计算索引值,并重新生成桶。
因此在使用 Dictionary 时,仍然建议指定一个初始的 Size 值以控制扩容的次数。
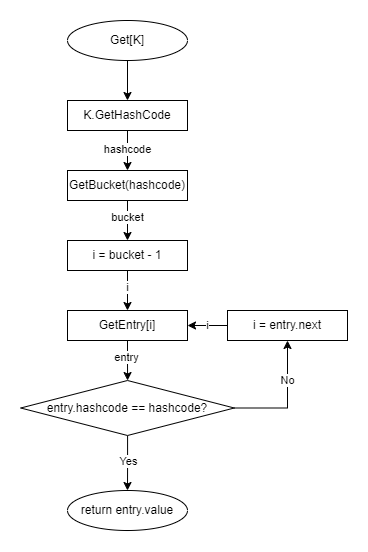
3. 数据查找
在上文中已得知数据的存储方式,不难想象到查找的原理。
查找时,同样先获得 Key 的哈希值,然后对 Size 取余,获取到对应的桶索引,最后再遍历桶来获得对应哈希值的数据。
参考以下流程图:
二、关于遍历
在对 Dictionary 的值进行遍历时一般有几种方法。
直接遍历键值对:
foreach (KeyValuePair<string,int> pair in dictionary) {
Console.WriteLine(pair.Value);
}或是遍历值集合:
foreach (int i in dictionary.Values) {
Console.WriteLine(i);
}这两种遍历方法在性能上是否有差距?
在使用 BenchmarkDotNet 进行测试后,得出的结论是:无明显差异。
1. Benchmark 测试
以下测试基于 .net 8.0 环境。
使用的测试代码如下:
[CsvExporter]
[MemoryDiagnoser]
[SimpleJob(RuntimeMoniker.Net80)]
public class DictionaryBenchmark {
private Dictionary<string, int> dictionary;
[Params(10_000, 100_000)]
public int n;
[GlobalSetup]
public void Setup() {
dictionary = new Dictionary<string, int>();
for (int i = 0; i < n; i++) {
dictionary.Add(i.ToString(), i);
}
}
[Benchmark]
public void ForeachByValues() {
foreach (int i in dictionary.Values) {
// ignore
}
}
[Benchmark]
public void ForeachByPair() {
foreach (KeyValuePair<string,int> pair in dictionary) {
// ignore
}
}
}测试结果如下:
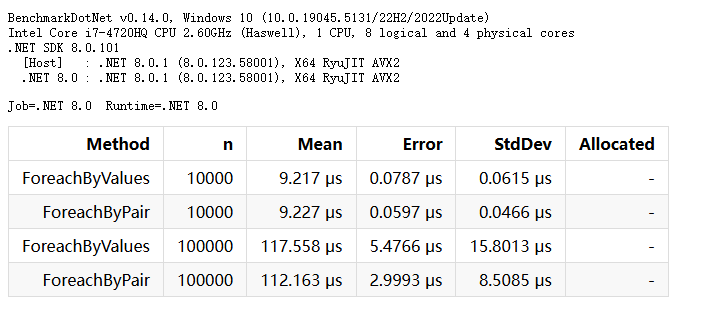
其中,n是 Dictionary 中的元素数量, Mean 是所有运行结果的算术平均值。Allocated 是分配的堆内存数。
可以看到两种遍历方法的速度没有非常明显的差距。并且没有产生堆内存分配。
2. 源码解读
首先,通过 foreach 进行遍历时其原理均是使用了迭代器 Enumerator ,迭代器根据保存的状态来取得下一个值,通过查看其 MoveNext 方法实现可以知道其是如何获得下一个值的。
这种设计的好处是不用创建临时集合,减少了内存分配的开销。
在 Dictionary 中,遍历键值对返回为 IEnumerator<KeyValuePair<TKey, TValue>> 类型的迭代器。
其 MoveNext 方法如下:
public bool MoveNext()
{
if (_version != _dictionary._version)
{
ThrowHelper.ThrowInvalidOperationException_InvalidOperation_EnumFailedVersion();
}
// Use unsigned comparison since we set index to dictionary.count+1 when the enumeration ends.
// dictionary.count+1 could be negative if dictionary.count is int.MaxValue
while ((uint)_index < (uint)_dictionary._count)
{
ref Entry entry = ref _dictionary._entries![_index++];
if (entry.next >= -1)
{
_current = new KeyValuePair<TKey, TValue>(entry.key, entry.value);
return true;
}
}
_index = _dictionary._count + 1;
_current = default;
return false;
}上文已经提到过,在 Dictionary 内部,每个键值对本身被封装为 Entry 对象中,并保存在 entries 数组中,因此遍历键值对时直接遍历该数组即可。不过因为 Entry 是一个非公开的 private 结构,最后会将其重新封装为 KeyValuePair 并返回。
由于 Entry 和 KeyValuePair 都为值类型的 struct ,因此这个过程也并未产生堆内存分配。
同样的我们可以查看值集合 ValueCollection 所返回的迭代器的实现:
public bool MoveNext()
{
if (_version != _dictionary._version)
{
ThrowHelper.ThrowInvalidOperationException_InvalidOperation_EnumFailedVersion();
}
while ((uint)_index < (uint)_dictionary._count)
{
ref Entry entry = ref _dictionary._entries![_index++];
if (entry.next >= -1)
{
_currentValue = entry.value;
return true;
}
}
_index = _dictionary._count + 1;
_currentValue = default;
return false;
}可以看到整体结构几乎没有区别,因此也印证了没有性能差异这一测试结果。
在 .Net 中关于 Dictionary (哈希表) 的一些细节
https://lunarconcerto.cafe/archives/details-about-dotnet-dictionary
Comments